
Auf deutsch übersetzt ist ein Data Vault ein Datentresor. Das bedeutet wohl, dass die Daten sicher sind, dass sie nicht mehr verloren gehen.
In Wikipedia kann man über „Data Vault“ von Dan Linstedt folgendes lesen:
Data Vault ist eine Modellierungstechnik für Data Warehouses, die insbesondere für agile Data Warehouses geeignet ist. Sie bietet eine hohe Flexibilität bei Erweiterungen, eine vollständige unitemporale Historisierung der Daten und erlaubt eine starke Parallelisierung der Datenladeprozesse.
aus https://de.wikipedia.org/wiki/Data_Vault, abgerufen am 23.3.2024
In dieser kurzen Beschreibung sind die wichtigsten Features dieses Data Warehouse Konzepts bereits enthalten:
- Flexibilität bei Erweiterungen
- Historisierung der Daten, selbst wenn die Quellsysteme keine Historisierung bieten
- Parallelisierung der Datenladeprozesse
Wie werden diese Ziele mit Data Vault 2.0 (DV2.0) erreicht?
- Die Daten der Quellsysteme werden ohne fachliche Bereinigung und Transformation im Data Warehouse (im Raw Vault) abgelegt. Es handelt sich hier also eher um einen ELT- als um einen ETL-Prozess (Extract-Load-Transform statt Extract-Transform-Load). Dadurch entspricht der Stand im Data Warehouse immer dem Stand der operativen Systeme zum Zeitpunkt der Übernahme in das Data Warehouse.
- Unterschiedliche Datenbestände der Quellsysteme (verschiedene Versionen oder Daten aus verschiedenen Quellsystemen) werden auch im Raw Vault getrennt abgelegt. Deshalb können die Datenladeprozesse parallel ausgeführt werden.
- Die Daten der Quellsysteme werden periodisch in einer Staging-Umgebung bereitgestellt. Dadurch werden Snapshots der operativen Daten erfasst, die zur Historisierung der Daten im Data Warehouse verwendet werden.
- Aus der Staging-Umgebung werden die veränderten Daten in den Raw Vault übernommen (jede Änderung führt zu einem neuen Datenstand).
- Fachliche Transformationen der Daten im Raw Vault bilden den Business Vault.
- Wenn die Daten der Staging-Umgebung archiviert werden, dann spricht man von einer Persistent Staging Area (PSA). Wenn eine PSA vorhanden ist, dann kann das Data Warehouse jederzeit gelöscht und mit der Historie aus der PSA komplett neu aufgebaut werden. So können Fehler beim Aufbau des DWH korrigiert werden, auch wenn sie erst spät erkannt werden.
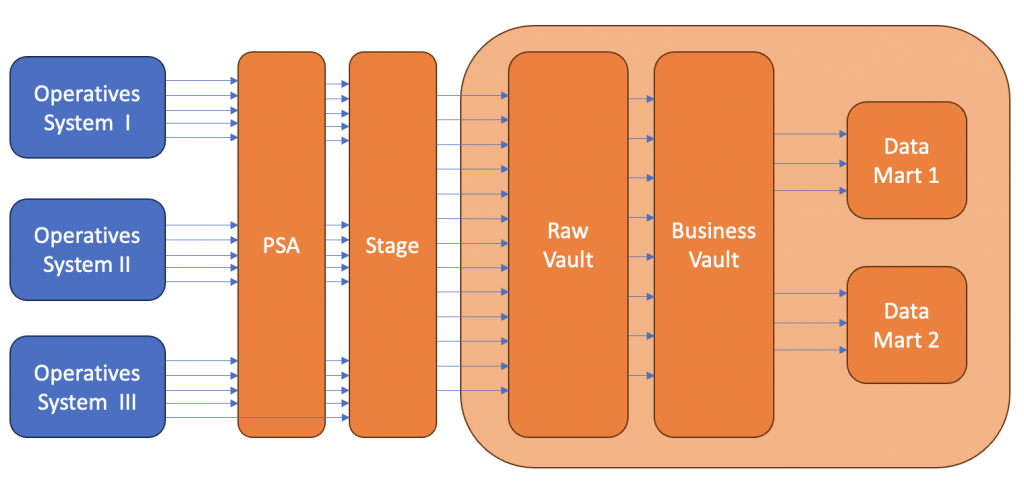
In diesem Bild wird der Weg der Informationen aus den operativen Systemen über die PSA und die Stage in das DWH gezeigt.
Das DWH besteht
- aus dem Raw Vault, in dem die Daten aus den Quellsystemen ohne fachliche Bereinigung abgelegt sind
- aus dem Business Vault, in dem die bereinigten Daten aus dem Raw Vault abgelegt sind und
- aus den Data Marts, in denen die Informationen in der Form aufbereitet werden, wie sie für die weitere Benutzung benötigt werden. Siehe hierzu auch die Beschreibung von Data Marts im Beitrag „Reporting für kleinere Unternehmen“.
Hubs, Links und Satellites
Der Raw Vault speichert die Daten aus den Stage-Tabellen in drei Tabellen-Typen:
- Hubs: hier werden die natürlichen Schlüssel (Natural Keys) der Daten abgelegt. Beispiele sind Kundennummern, Vertragsnummern und Produktschlüssel. Alle Natural Keys, die in den operativen Systemen vorkommen, werden hier gespeichert. Auch „falsche“ Natural Keys werden hier abgelegt, wenn sie in den Daten vorkommen. Es werden keine weiteren Daten neben den Natural Keys gespeichert. Hubs werden aus allen Stage-Tabellen gespeist, in denen der Natural Key des Hubs enthalten ist. Hub-Datensätze werden nur dann geschrieben, wenn sie im Hub noch nicht vorhanden sind.
- Links: hier werden Kombinationen von natürlichen Schlüsseln abgelegt, die in den operativen Systemen vorkommen. Beispiele sind die Zuordnung von Verträgen zu Kunden und die Zuordnung von Produkten zu Verträgen. Alle Kombinationen, die in den operativen Systemen vorkommen, werden hier gespeichert. Auch Kombinationen, die nicht mehr gültig sind, oder Kombinationen, die aufgrund von Fehleingaben im operativen System erfasst worden sind, werden hier abgelegt. Es werden keine weiteren Daten neben den Kombinationen der Natural Keys gespeichert. Links werden aus allen Stage-Tabellen gespeist, in denen die Kombination der Natural Keys des Links enthalten ist. Link-Datensätze werden nur dann geschrieben, wenn sie im Link noch nicht vorhanden sind.
- Satellites: hier werden alle Daten abgelegt, die zu einem Hub oder einem Link gehören. Satelliten beziehen sich immer genau auf einen Hub oder genau auf einen Link. Die Daten eines Satelliten stammen aus genau einer Datenquelle, d.h. sie kommen aus genau einem operativen System und genau einer Stage-Tabelle. Die Daten in Satelliten sind historisiert. Jede Veränderung dieser Daten in der Stage-Tabelle aus dem operativen System werden hier im Satelliten protokolliert.
Da Hubs und Links nur die Natural Keys enthalten, können sie aus allen Stage-Tabellen ohne Rücksicht auf andere Informationen jederzeit gefüllt werden. Hub- und Link-Datensätze werden nie gelöscht, da Hubs und Links keine Informationen über die Gültigkeit der Daten enthalten.
Da sich Satelliten immer genau auf einen Hub oder genau auf einen Link beziehen und immer aus genau einer Stage-Tabelle übernommen werden, können sie ohne Rücksicht auf andere Stage-Tabellen jederzeit gefüllt werden. Satelliten-Datensätze werden nur dann geschrieben, wenn sich die Daten gegenüber dem vorherigen Stand verändert haben.
Diese klare Strukturierung der Tabellen ist die Basis für die eingangs erwähnten Features der Modellierungsmethode Data Vault: Parallelisierung, Historisierung und Flexibilität.
Auch der Business Vault, in dem die fachlich bereinigten und transformierten Daten abgelegt werden, wird aus Hubs, Links und Satellites gebildet.
Für einen Überblick zu DV2.0 empfehle ich diese YouTube-Serie von data-vault.com. Hier werden die Prinzipien in 7 kleinen YouTube-Filmen vorgestellt: https://youtube.com/playlist?list=PLPz42gh12w04u1VKr4R5Cwbg3EvD1aZdC&feature=shared
In Folge 5 von 7 wird die Modellierung eines Beispiels in Hubs, Links und Satellites beschrieben.
Vom Erfinder von Data Vault 2.0 selbst, von Dan Linstedt, gibt es das Buch „Building a Scalable Data Warehouse with Data Vault 2.0“. Hier beschreibt er umfassend, wie ein Data Warehouse mit Data Vault 2.0 aufgebaut wird.
Nach dieser kurzen Einführung in DV2.0 möchte ich eine technische Lösung vorstellen, mit der auch kleine Unternehmen ein DWH nach DV2.0 implementieren können. Das beschreibe ich im nächsten Beitrag „Ein DWH mit git, Linux, Docker, PostgreSQL, dbt und AutomateDV“.
Schreibe einen Kommentar