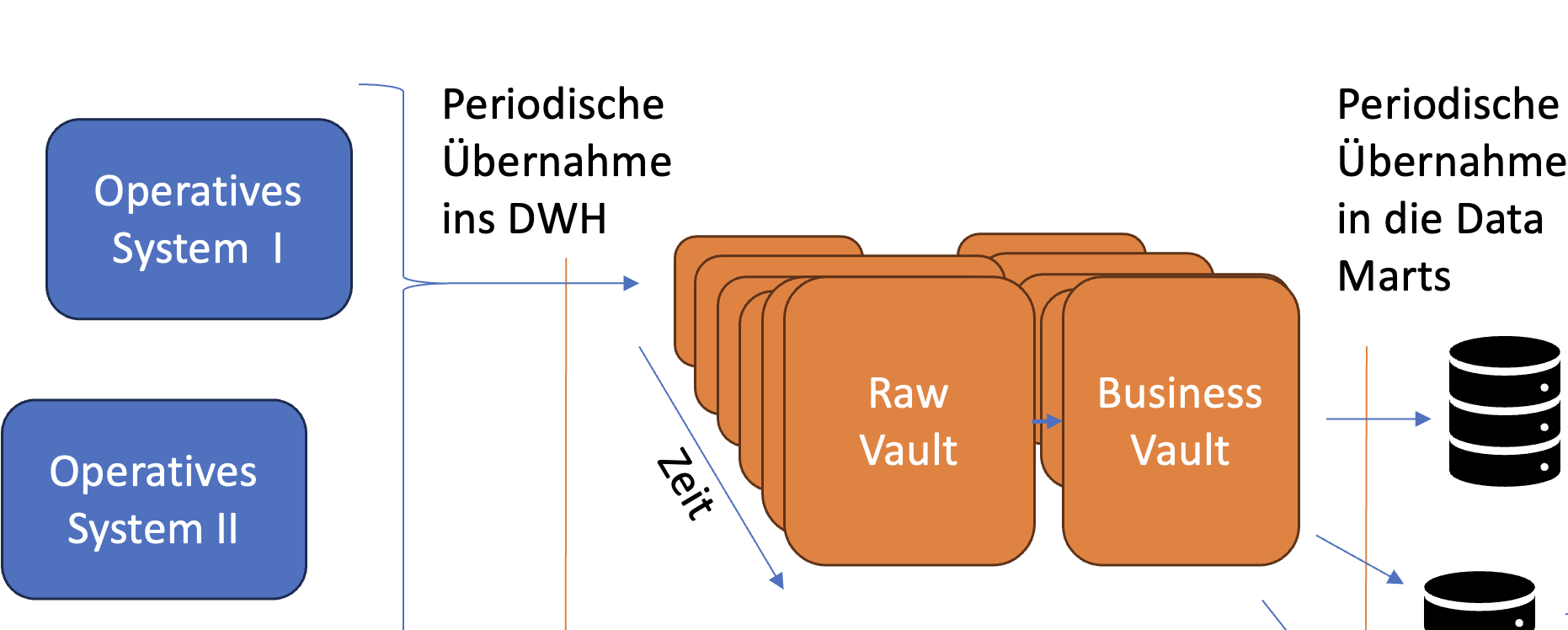
Was braucht man, um ein Data Warehouse (DWH) zu betreiben?
Ich stelle ihnen hier eine Lösung vor, die einen virtuellen Server benötigt, auf dem das DWH betrieben werden kann. Außer diesem virtuellen Server, für den monatliche Kosten anfallen, den Personalkosten für die DWH-Mitarbeiter und den Kosten für Training und Beratung werden nur Komponenten eingesetzt, die kostenfrei zur Verfügung stehen.
Bei der Umsetzung der DWH-Funktionalität setzen wir Tools wie dbt und AutomateDV ein, die nur einen geringen Konfigurationsaufwand erfordern und viele Features bereits out-of-the-box mitliefern.
Sowohl beim System als auch bei den DWH-Prozessen nutzen wir die Features der verwendeten Systeme möglichst ohne jede individuelle Erweiterung oder Anpassung.
Diese Lösung ist damit besonders für kleine und mittlere Unternehmen geeignet, in denen üblicherweise nur wenige Personen für den Aufbau und den Betrieb eines solchen Systems zur Verfügung stehen.
Die Basis (Systeme und Software)
Linux-Server
Wir benötigen zunächst einen Rechner, auf dem die DWH-Software und die DWH-Datenbank betrieben wird. Dafür verwenden wir einen virtuellen Server, den wir entweder selbst hosten oder bei einem Cloud Service Provider hosten lassen. Er soll ein Linux-Betriebssystem und genug freien Speicherplatz für unser DWH haben. Außerdem sollen die Daten des Servers in ein Backup-Konzept eingebunden sein.
Docker-Umgebung
In dem Linux-Betriebssystem betreiben wir unser DWH in einer Docker-Umgebung. Dadurch können wir in der Docker-Umgebung genau die Software in genau der Version bereitstellen, die wir für unsere DWH-Anwendung benötigen.
Die Docker-Umgebung eines DWH besteht aus dem Docker-Container für die DWH-Applikation dwh-app und dem Docker-Container für die DWH-Datenbank dwh-db.
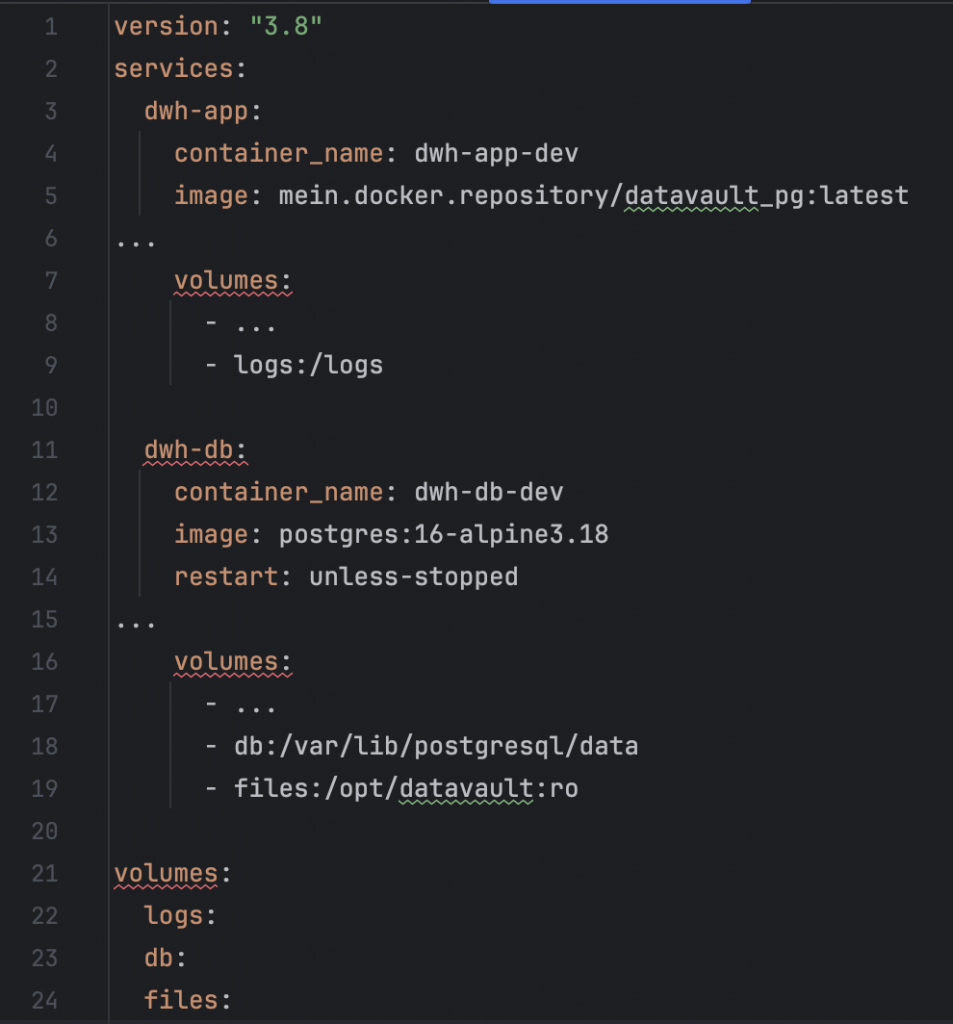
Wir können so auf einem Server auch mehrere Stages betreiben: eine Development-, eine Test- und eine Produktionsumgebung.
Zur Docker-Umgebung gehört auch ein Docker Repository, in dem die Images der DWH-Applikation abgelegt werden.
PostgreSQL-Datenbank
Bei der Datenbank entscheiden wir uns für eine PostgreSQL-Datenbank, da sie mit einer freien Open-Source-Lizenz bereitgestellt wird und deshalb keine Lizenzkosten für die Datenbank anfallen. Erste Versuche, die wir mit einer freien MS-SQLServer-Express-Datenbank durchgeführt haben, funktionierten nur bis zu einer DB-Größe von ca. 10 GB.
git-Repository
Die Software für unser DWH wird in einem git-Repository abgelegt. Wir nutzen dafür ein Azure DevOps Projekt. Das git-Repository wird in Azure DevOps-Projekten kostenfrei zur Verfügung gestellt.
Continuous Integration
Jeder neue Stand der DWH-Prozesse, der im git-Repository gespeichert wird, triggert einen automatischen Build der Docker-Umgebung.
dbt
Die Software, in der die DWH-Prozesse abgebildet werden, basiert auf dem Tool dbt:
data build tool (dbt) is an open-source command line tool that helps analysts and engineers transform data in their warehouse more effectively.[2]
aus https://en.wikipedia.org/wiki/Data_build_tool, abgerufen am 31.03.2024
In dbt werden die Transformationen mit Select-Statements und yaml-Konfigurationen beschrieben. Das dbt-Tool generiert daraus die ausführbaren Programme und die Dokumentation der Prozesse.
Diese Software wird im Docker-Container dwh-app bereitgestellt.
AutomateDV
Die Data Vault 2.0 Modellierung im DWH wird mit der dbt Package AutomateDV umgesetzt:
AutomateDV is a dbt package that generates & executes the ETL you need to build a Data Vault 2.0 Data Warehouse.
aus https://automate-dv.readthedocs.io/en/latest/, abgerufen am 31.03.2024
Diese Software wird im Docker-Container dwh-app bereitgestellt.
Weitere Skripte zur Automatisierung der Prozesse
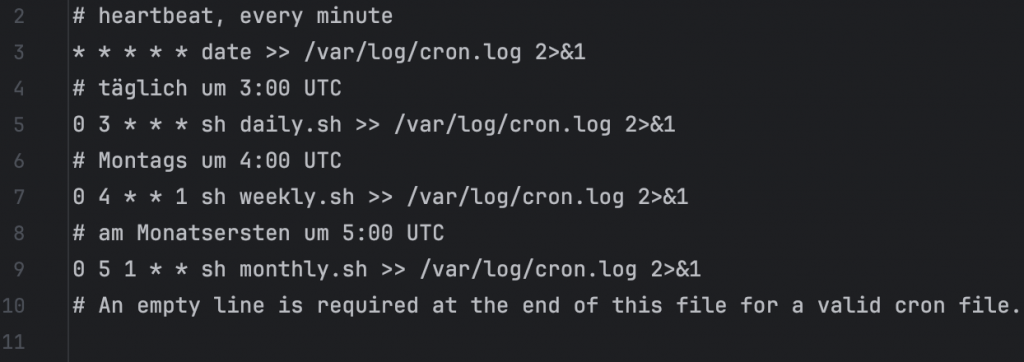
Für die Automatisierung werden Skripte verwendet, die im Docker-Container dwh-app über cron gesteuert werden. So können tägliche, wöchentliche oder monatliche Bereitstellungen und Aufbereitungen der Daten konfiguriert werden.
Die Skripte sind in Powershell 7 geschrieben. Powershell 7 wurde als Plattform-übergreifende Skriptsprache gewählt, da so auch eine Implementierung unter Windows vorstellbar ist.
IDE
Zur Entwicklung der DWH-Software sollte eine IDE (Integrated Development Environment) verwendet werden.
Wir haben uns für die Community Edition der IntelliJ IDEA entschieden.
Database Tool
Für die Verwaltung der PostgreSQL-Datenbank und zum Testen und Evaluieren von Select-Statements zum Datenbank-Zugriff nutzen wir das Database Tool DBeaver Community.
Die Inhalte
Alle Definitionen und Transformationsregeln des DWH werden in der IDE entwickelt und im git-Repository gespeichert.
Die DWH-Prozesse erledigen die folgenden Aufgaben:
- Export der benötigten Tabellen der operativen Systeme (OpSys) in CSV-Dateien (Skript)
- Laden der CSV-Dateien in die DWH-Datenbank in ein OpSys-Schema (Skript)
- Laden der Daten aus dem OpSys-Schema in die Persistent Staging Area (dbt)
- Aufräumen der Persistent Staging Area, damit nur Monatsultimo-Stände aufbewahrt werden (Skript)
- Bereitstellen der aktuellen Ladedaten in der Raw-Stage (dbt)
- Laden der Stage-Tabellen des Raw Vault (AutomateDV)
- Laden der Hubs, Links und Satellites des Raw Vault (AutomateDV)
- Erstellen der Views auf den Raw Vault (dbt)
- Ausführen der Bereinigungen und Transformationen in der Raw-Stage des Business Vault (dbt)
- Laden der Stage-Tabellen des Business Vault (AutomateDV)
- Laden der Hubs, Links und Satellites des Business Vault (AutomateDV)
- Laden der Data Marts aus dem Business Vault und dem Raw Vault (dbt)
Diese Prozesse laufen täglich, wöchentlich oder monatlich. Sie werden im Docker-Container dwh-app über cron gesteuert.
Alle mit dbt oder AutomateDV gekennzeichneten Prozessschritte sind in der automatisch generierten dbt-Dokumentation enthalten und beschreiben so die gesamte Transformation aus den operativen Systemen über den Raw Vault und den Business Vault bis zu den Data Marts.

In den nächsten Monaten möchte ich verschiedene Teile dieser Lösung im Detail vorstellen. Wenn Sie also an bestimmten Themen besonders interessiert sind, dann freue ich mich über ihre Vorschläge!
Mein nächster Post soll sich aber mit der Kraft der Abstraktion beschäftigen. Ich werde zeigen, warum es gut und sogar unerläßlich ist, gewisse Dinge immer auf die gleiche Art zu tun und dann auch nicht mehr darüber nachzudenken, warum.
Schreibe einen Kommentar